On Inodes and the Inode Pointer Structure (2024-07-30)
Inodes are a fundamental part of the data structure that stores and references all data available on a storage device.
File Names Are References
The way files and directories are abstracted the end user typically thinks of files being nested. However, this isn't truly the case. Directories are simply lists of inode and file name pairs of the file names underneath, the name of the parent, and the name of itself. An inode is an entity that has a unique number and contains the file metadata, and pointers to the actual data the file "contains". That's it. Inodes do not store their "names" and all the filesystem really cares about are the inodes. File names are essentially just a human readable label mapped to an inode.
What Does An Inode Contain And Reference?
Inodes are where the file's metadata is stored. However, the data itself is not there. The data is referenced through a system of pointers also stored in the inode.
Typical Inode Pointer Structure
The typical pointer structure is implemented in ext* filesystems among others. It has the following qualities:
- *inode pointer structure:
- 12 direct pointers that directly point to blocks of the file's data
- 1 singly indirect pointer (pointing to a block of direct pointers)
- 1 doubly indirect pointer (pointing to a block of single indirect pointers)
- 1 triply indirect pointer (pointing to a block of doubly indirect pointers)
- fixed block size (increase redirection when required, data can be stored non contiguously
- inodes assigned fixed amount at filesystem instantiation, amount of indirect blocks are not fixed
- number of pointers dependent on block size and size of pointers The pointers are set up to use direct pointers and others with varying levels of indirection. This is so that the structure can support varying amounts of data while remaining static. If more space is needed, the system can simply use any unclaimed data block at some far off address through redirection.
Pointers and Metadata
Here is a diagram of the structure of inodes:
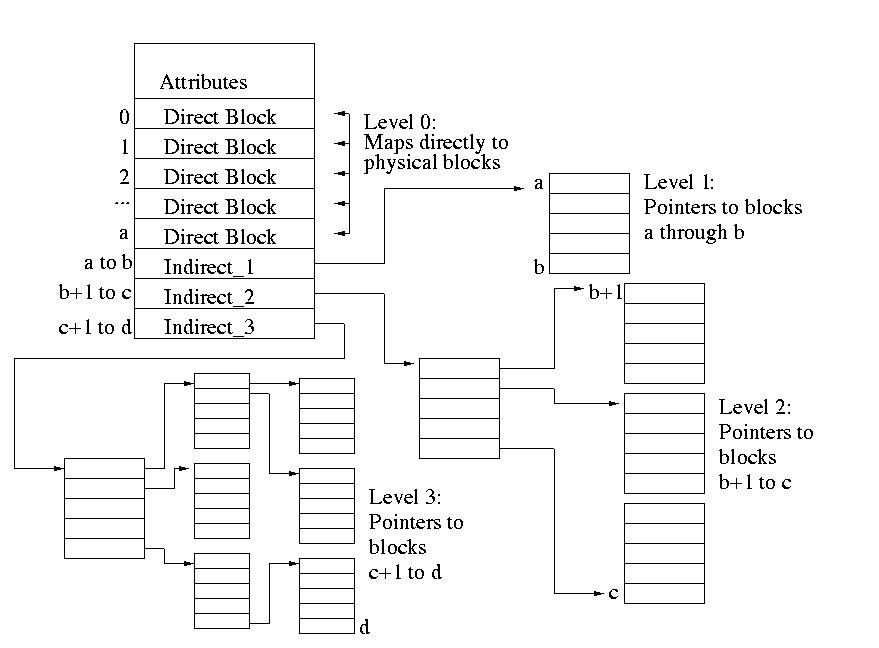
You can see the structure of the pointers that were previously discussed. However, the undiscussed metadata section is present as well. This section contains metadata such as filer permissions, ownership, edit history, etc. An exact list of metadata in an inode will be provided in the next subsection.
Viewing Contents of Inodes
The contents of inodes can be viewed using the stat system call.
stat test.txt
File: test.txt
Size: 15 Blocks: 8 IO Block: 4096 regular file
Device: 259,2 Inode: 30158006 Links: 3
Access: (0644/-rw-r--r--) Uid: ( 1001/ steve) Gid: ( 1001/ steve)
Access: 2024-07-26 08:23:43.390310050 -0700
Modify: 2024-07-26 08:24:02.074309630 -0700
Change: 2024-07-28 13:29:14.971830641 -0700
Birth: 2024-07-26 08:23:43.390310050 -0700
This command lists the contents of the inode test.txt is paired to. The metadata an inode contains includes:
- File Type: Indicates the type of file (e.g., regular file, directory, symbolic link).
- Permissions: Specifies read, write, and execute permissions for the owner, group, and others.
- Owner User ID (UID): The user ID of the file's owner.
- Owner Group ID (GID): The group ID of the file's owner group.
- File Size: The size of the file in bytes.
- Number of Hard Links: The count of hard links pointing to this inode.
- Timestamps:
- Access Time (atime): Last time the file was accessed.
- Modification Time (mtime): Last time the file content was modified.
- Change Time (ctime): Last time the inode metadata was changed.
- File Size in Blocks: The number of blocks allocated to the file.
- Extended Attributes: Additional metadata such as security labels or custom attributes.
- Flags: File flags indicating special characteristics or behaviors (e.g., immutable, append-only).
- Generation Number: A number that changes each time the inode is reused, used to detect stale file handles.
- File System Identifier: An identifier for the file system where the inode resides.
- The device ID of the file if it is a device file. Links are discussed in the next section.
Hard Links and Soft Links
Hard Links Are Names
File names are known as hard links. And the nature of the inode structure inherently allows files to have multiple hard links. the -i option on various commands outputs information on a file's inodes.
30158006 .rw-r--r-- 15 steve 26 Jul 08:24 test.txt
Here ls -li long lists with the inode number. So test.txt is mapped to inode 30158006. To create a hard link the command ln is used.
ln test.txt hard_link_to_test.txt
This command creates a hard link named hard_link_to_test.txt to test.txt.
ls -li test.txt hard_link_to_test.txt
30158006 .rw-r--r-- 15 steve 26 Jul 08:24 hard_link_to_test.txt
30158006 .rw-r--r-- 15 steve 26 Jul 08:24 test.txt
Here we can see that these two files share the same inode number: 30158006. This means that both file names are mapped to that inode and thus are referencing the same data.
Soft Links Are Pointers To Names
There is also the concept of a soft link aka a symbolic link. These links are file names that are pointers to other names. A soft link can be created with the -s option as in ln -s.
ln -s test.txt soft_link_to_test.txt
This command creates a soft link named soft_link_to_test.txt to test.txt.
ls -li test.txt hard_link_to_test.txt soft_link_to_test.txt
30158006 .rw-r--r-- 15 steve 26 Jul 08:24 hard_link_to_test.txt
30157667 lrwxrwxrwx 8 steve 28 Jul 13:37 soft_link_to_test.txt -> test.txt
30158006 .rw-r--r-- 15 steve 26 Jul 08:24 test.txt
Here we can see that the soft link does not share the inodes of the hard links but has its own. That is because it is pointing to the file name test.txt and not mapped to that filename's inode as a hard link would be. A soft link is mapped to its own inode, and that inode contains the path of the file being pointed to.
To unlink a link the unlink command can be used.
unlink hard_link_to_test.txt
╭─steve@kathy-office ~/test
╰─❯ unlink soft_link_to_test.txt
╭─steve@kathy-office ~/test
╰─❯ ls -li test.txt hard_link_to_test.txt soft_link_to_test.txt
"hard_link_to_test.txt": No such file or directory (os error 2)
"soft_link_to_test.txt": No such file or directory (os error 2)
30158006 .rw-r--r-- 15 steve 26 Jul 08:24 test.txt
Link Use Cases
Hard Links
I've seen hard links described as a "poor man's backup" which means that if one filename is deleted the inode isn't inaccessible. There is still some other name mapped to that inode. When a file is deleted via something like rm, the data still exists. This will be covered in a later section. This also saves space, if what is hard linked in large, but needs to exists in multiple paths. And since inodes store metadata such as permissions and file attributes, the hard link will share them as well.
Soft Links
Soft links allow for having files accessible from multiple paths without moving or copying anything. Another use is version management. Say there is one service or script that runs and depends on something having a certain path or name. but it changes regularly. A soft link to it won't. So instead of rewriting anything, the soft link can just be redirected. Soft links also have the capability of linking to files across filesystems and devices, where hard links can't.
Restrictions
Linking has some limitations due to the inherent structure of filesystems and inodes.
Linking To Directories
Directories can not be hard linked in Linux. Historically this has been possible, but most operating systems disable this behavior now to avoid cycles. A notable counterexample is that a superuser can make hard links to directories in MacOS 10.5. Directories can be soft linked because a soft link's inode just contains the path of the file being pointed to.
Inode Exhaustion
Filesystems have a limited and fixed number of inodes for use, and all data stored needs an inode pointing to it. If one created countless small files containing nothing each would require an inode and they would eventually run out, and no more files can be created. This is known as inode exhaustion. And since the files were empty there wold still be ample free space, and everything would appear fine on the surface. The number of available inodes can be checked using df -i.
df -i
Filesystem Inodes IUsed IFree IUse% Mounted on
udev 1.7M 535 1.7M 1% /dev
tmpfs 1.7M 936 1.7M 1% /run
/dev/nvme0n1p2 58M 606K 57M 2% /
tmpfs 1.7M 712 1.7M 1% /dev/shm
tmpfs 1.7M 6 1.7M 1% /run/lock
tmpfs 1.7M 94 1.7M 1% /tmp
/dev/nvme0n1p1 0 0 0 - /boot/efi
tmpfs 348K 106 348K 1% /run/user/1001
Based on this output we can see I have plenty of inodes free.
Setting Number of Inodes in Filesystem
Since the amount of inodes are fixed the only way to alter it is to set it at filesystem creation. Say we are creating an ext4 filesystem. The mkfs.ext4 can do this. The following is from its man page:
>-N number-of-inodes
Overrides the default calculation of the number of inodes that should be reserved for the file system (which is based on the number of blocks and the bytes-per-inode
ratio). This allows the user to specify the number of desired inodes directly.
Note that there are some exceptions. For instance Btrfs is capable of dynamically allocating inodes so the amount is not fixed.
Alternative Structures and Filesystems
Many filesystems exist that are fundamentally different that something like ext*. They do not use inodes but utilize other data structures such as B-trees. The following is a list of filesystems that do not use inodes:
- FAT (File Allocation Table): Used by MS-DOS and early versions of Windows, FAT file systems, including FAT12, FAT16, and FAT32, use a file allocation table to manage files rather than inodes.
- exFAT (Extended File Allocation Table): Designed by Microsoft to replace FAT32, exFAT is optimized for flash drives and does not use inodes.
- ReFS (Resilient File System): Developed by Microsoft, ReFS uses B-trees for metadata storage and does not use inodes.
- HFS (Hierarchical File System): Used in older Apple Macintosh systems, HFS uses a catalog file and extents overflow file for metadata instead of inodes.
- HFS+ (Hierarchical File System Plus): An updated version of HFS used in macOS before APFS, HFS+ uses B-trees for metadata storage, avoiding the inode structure.
- APFS (Apple File System): The current file system for macOS and iOS, APFS uses container and volume structures with object identifiers instead of inodes.
- NTFS (New Technology File System): Used by modern versions of Windows, NTFS uses a Master File Table (MFT) to store metadata rather than inodes.
- IBM GPFS (General Parallel File System): Now known as Spectrum Scale, GPFS uses a distributed metadata model with descriptors rather than traditional inodes.
Retrieving Unclaimed Data
Recall that when a hard link is deleted via rm the data still exists, however once the last hard link to the inode is gone the metadata is deleted and there is no way to access the data. The data still exists but the space it occupies is now unclaimed can be reclaimed and overwritten by new data. If data needs to be recovered cease all writes immediately. Either unmount the drive or boot into a live environment. The drive can not be written to until the data is located. There are a number of programs that can inspect data fields for information indicating the types of data stored there. They may utilize a technique of data recovery known as file carving in which data is reconstituted from fragments.
In conclusion, understanding inodes is a critical part of understanding linking and the filesystems used on Linux.